2025. 7. 7. 오후 4:27:40
“너도 나도 포스트그레SQL, EDB를 택해야 하는 이유” – 바이라인네트워크
출처: 바이라인네트워크 ( 한국 / 한국어 )
관계형 데이터베이스는 데이터를 테이블 형태로 구성하여 관리하는 데이터베이스 모델이다. 1970년 IBM의 E.F. 코드에 의해 처음 정의되었으며, 데이터베이스의 핵심 개념인 테이블, 열, 행, 키, 관계 등을 포함한다. 관계형 데이터베이스 관리 시스템(RDBMS)은 이러한 관계형 데이터베이스를 관리하기 위한 소프트웨어로, ACID 트랜잭션, 저장 프로시저, 정규화, 인덱스 등의 기술을 활용한다. 오라클, MySQL, Microsoft SQL Server 등이 주요 RDBMS 제품이며, 고객 관리, 판매 관리 등 다양한 분야에서 활용된다.
| 관계형 데이터베이스 | |
|---|---|
| 지도 | |
| 일반 정보 | |
| 유형 | 데이터베이스 |
| 개발자 | 에드가 F. 코드 |
| 최초 구현 | 1970년 |
| 다른 이름 | 관계형 DBMS, RDBMS |
| 특징 | |
| 데이터 모델 | 관계형 모델 |
| 스키마 | 고정 스키마 |
| 질의 언어 | SQL |
| 데이터 무결성 | ACID 속성 |
| 주요 기능 | 데이터 저장, 검색, 업데이트, 삭제, 관리 |
| 기술적 측면 | |
| 데이터 구조 | 테이블, 관계 |
| 인덱싱 | B-트리, 해시 테이블 |
| 저장 방식 | 디스크, SSD |
| 접근 방식 | 클라이언트-서버 모델 |
| 표준 및 규격 | |
| SQL 표준 | SQL:1999, SQL:2003, SQL:2008, SQL:2011, SQL:2016 |
| ACID 준수 | 부분적으로 또는 전체적으로 준수 |
| 구현 | |
| 주요 제품 | 오라클 데이터베이스 MySQL PostgreSQL Microsoft SQL Server IBM Db2 SQLite |
| 관련 기술 | |
| 데이터베이스 설계 | 데이터 모델링, 정규화 |
| 질의 최적화 | 질의 계획, 인덱스 |
| 트랜잭션 관리 | 잠금, 병행 제어 |
| 장점 | |
| 데이터 일관성 | ACID 속성을 통한 데이터 무결성 유지 |
| 쉬운 접근성 | SQL을 통한 간편한 데이터 접근 및 관리 |
| 유연성 | 다양한 데이터 모델링 및 질의 방법 지원 |
| 단점 | |
| 성능 문제 | 대용량 데이터 처리 시 성능 저하 가능성 |
| 복잡성 | 복잡한 관계 모델링 및 질의 필요 |
| 확장성 | 수직적 확장에 한계 존재 |
관계형 데이터베이스는 1970년 IBM의 에드거 커드가 처음 정의했다.[18] 그는 커드의 12 규칙을 통해 관계형 데이터베이스 시스템이 갖춰야 할 요건을 제시했다.
초기에는 계층형 데이터베이스와 네트워크 모형 등도 있었지만, 관계형 데이터베이스가 점차 주류로 자리 잡았다.
관계형 데이터베이스와 SQL의 주요 용어는 아래 표와 같다.
| SQL 용어 | 관계형 데이터베이스 용어 | 설명 |
|---|---|---|
| 로우 | 튜플 또는 레코드 | 하나의 항목을 대표하는 데이터 |
| 컬럼 | 속성(어트리뷰트) 또는 필드 | 튜플의 이름 요소 (예: "주소", "생년월일") |
| 테이블 | 관계 또는 기초 관계변수 | 같은 속성을 공유하는 튜플의 모임 (컬럼이나 로우의 모임) |
| 뷰 또는 결과 집합 | 파생 관계변수 | 튜플들의 모임 (질의어에 응답하는 RDBMS의 데이터 보고서) |
코드의 규칙을 모두 만족하는 상업적 구현은 없었지만, 점차 다음 조건을 만족하는 시스템을 RDBMS라고 부르게 되었다.
# 데이터를 관계(테이블의 모음)로 표현
# 관계 연산자 제공
2009년 기준으로 대부분의 상업용 RDBMS는 SQL을 쿼리 언어로 사용한다.[12]
에드거 커드는 1970년 6월 IBM 산호세 연구소에서 관계형 모델을 처음 정의하였다.[30] 이 모델은 데이터를 테이블(또는 관계) 형태로 구성하며, 각 레코드 (또는 튜플)는 고유 키로 식별된다.[31] 테이블은 일반적으로 고객이나 제품 같은 엔티티 타입을 나타내며, 레코드는 "Lee"와 같은 엔티티 인스턴스, 컬럼은 주소나 가격 같은 속성 값을 나타낸다.
각 레코드는 고유 키를 가지며, 외래 키를 사용하여 다른 테이블의 레코드와 연결할 수 있다. 관계는 테이블 간에 존재하며 일대일, 일대다, 다대다 형태가 있다. 대부분의 관계형 데이터베이스는 각 레코드의 각 컬럼이 하나의 값만 가지도록 설계한다.
커드의 12 규칙은 커드의 관계형 모델 관점을 요약하며, 계층적 데이터베이스 모형, 네트워크 모형 등 다른 모델도 존재한다.
관계는 같은 속성을 가진 튜플의 모임이며, 일반적으로 물리적 객체나 개념을 나타내는 오브젝트와 그 정보를 표현한다. 관계는 컬럼으로 구성된 테이블로 기술되며, 속성이 참조하는 데이터는 동일한 도메인에 속하고 동일한 제약을 따른다.
제약(constraint)은 속성 범위를 제한하며, 예를 들어 1부터 10 사이의 정수로 제한할 수 있다. 각 속성은 관련 도메인을 가지며, '''도메인 제약'''이 존재한다. 관계형 모델의 주요 원칙은 '''개체 무결성'''과 '''참조 무결성'''이다.
관계 모델은 IBM의 에드거 F. 코드가 고안했으며,[29] 현재 가장 널리 사용되는 데이터 모델이다. 사용자는 쿼리를 통해 데이터를 검색하거나 변경할 수 있다.
데이터는 표와 유사한 관계(릴레이션)로 관리되며, 튜플(행), 속성(열), 도메인, 후보키, 외래키 등으로 구성된다. SQL 등 데이터베이스 언어(질의어)를 사용하여 관계 대수 연산 또는 관계 논리 연산을 수행하여 결과를 얻는다.
관계는 여러 개일 수 있으며 서로 연관될 수 있다. 예를 들어, 식품 통신 판매 회사의 고객 관리 데이터베이스에서 고객 목록과 물품 판매 목록은 별개지만 고객 번호 등으로 연결하여 정보를 추출할 수 있다.
: 식품 통신 판매 회사의 데이터베이스 예 (※ 데이터는 가상)
| 고객 번호 | 고객 이름 | 주소1 | 주소2 | 전화 번호 |
|---|---|---|---|---|
| 00001 | 아이다 타카유키 | 도쿄도 신주쿠구 | 가부키초 x-x-x | 03-xxxx-xxxx |
| 00002 | 이토 미카 | 가나가와현 요코하마시 | 나카구 야마시타초 xx | 045-xxx-xxxx |
| 00003 | 우치다 코지 | 사이타마현 사이타마시 | 타카사고 xx-xx | 048-xxx-xxxx |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 판매일 | 고객 번호 | 상품1 | 상품2 | 상품3 | …… |
|---|---|---|---|---|---|
| 050115 | 00002 | 긴죠 灘 1병 | 특선 안주 | ||
| 050116 | 00001 | 고베 와규 세트 | |||
| 050116 | 00003 | 특가 생햄 | 홀 머스타드 | 마리 로랑생 | |
| 050117 | 00001 | 사츠마 흑돼지 햄 | |||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
데이터 연결 기준인 키는 모든 데이터에 고유해야 한다. 잘 설계된 데이터베이스에서는 정형문(정형 쿼리)을 통해 최신 데이터를 기반으로 한 표를 볼 수 있다.
| SQL 용어 | 관계형 데이터베이스 용어 | 설명 |
|---|---|---|
| 행 | 튜플 또는 레코드 | 단일 항목을 나타내는 데이터 집합 |
| 열 | 속성 또는 필드 | 튜플의 레이블이 지정된 요소 (예: "주소", "생년월일") |
| 테이블 | 관계 또는 기본 relvar | 동일한 속성을 공유하는 튜플 집합 |
| 뷰 또는 결과 집합 | 파생 relvar | 쿼리에 대한 응답으로 RDBMS에서 제공하는 데이터 보고서 |
관계는 동일한 속성을 가진 튜플의 집합이다. 튜플은 일반적으로 객체와 해당 객체에 대한 정보를 나타낸다. 관계는 테이블로 표현되며, 행과 열로 구성된다. 속성이 참조하는 모든 데이터는 동일한 도메인에 있으며 동일한 제약 조건을 따른다.
관계형 모델은 관계의 튜플과 속성에 특정 순서가 없다고 명시한다. 애플리케이션은 ''select''(선택), ''project''(투영), ''join''(결합) 등의 연산을 사용하여 데이터에 접근한다. 관계는 ''insert''(삽입), ''delete''(삭제), ''update''(갱신) 연산자를 사용하여 수정할 수 있다.
튜플은 정의상 고유하며, 후보 또는 기본 키를 포함할 수 있다. 튜플의 속성은 정의상 슈퍼키를 구성한다.
모든 데이터는 릴레이션을 통해 저장되고 접근된다. 데이터를 저장하는 릴레이션을 "기본 릴레이션"(구현 시 "테이블")이라고 한다. 다른 릴레이션은 데이터를 저장하지 않고, 관계 연산을 통해 계산된다. 이러한 릴레이션을 "파생 릴레이션"(구현 시 "뷰" 또는 "쿼리")이라고 한다. 파생 릴레이션은 여러 릴레이션에서 정보를 가져오더라도 단일 릴레이션처럼 작동하며, 추상화 계층으로 사용될 수 있다.
도메인은 주어진 속성에 대한 가능한 값의 집합을 설명하며, 속성 값에 대한 제약 조건으로 간주될 수 있다. 제약 조건은 데이터베이스에서 비즈니스 규칙을 구현하는 한 가지 방법을 제공한다. SQL은 검사 제약 조건 형태로 제약 조건 기능을 구현한다.
제약 조건은 관계에 저장될 수 있는 데이터를 제한하며, 부울 값으로 생성되는 표현식을 사용하여 정의된다. 제약 조건은 단일 속성, 튜플 또는 전체 관계에 적용될 수 있다.
모든 속성에는 관련된 도메인이 있으므로 도메인 제약 조건이 있다. 관계형 모델의 두 가지 주요 규칙은 개체 무결성과 참조 무결성이다.
모든 관계/테이블은 기본 키를 가지며, 이는 관계가 집합이기 때문이다. 기본 키는 테이블 내에서 튜플을 고유하게 지정한다. 대리 키가 자주 사용되기도 한다.
복합 키는 레코드를 고유하게 식별하는 테이블 내의 두 개 이상의 속성으로 구성된 키이다.[19]
관계 모델에서 데이터는 표와 유사한 구조인 관계(릴레이션)로 관리된다. 관계는 튜플, 속성, 도메인, 후보키, 외래키 등으로 구성된다. SQL 등 데이터베이스 언어(질의어)를 사용하여 관계에 대해 관계 대수 연산 또는 관계 논리 연산을 수행하여 결과를 얻는다.
관계는 여러 개 존재할 수 있으며, 서로 연관될 수 있다. 예를 들어, 식품 통신 판매 회사의 고객 관리 데이터베이스에서 고객 목록과 물품 판매 목록은 별개의 데이터 집합이지만, 고객 번호 등으로 연결하여 정보를 추출할 수 있다.
: 식품 통신 판매 회사에서의 데이터베이스 예 (※ 데이터는 가상의 것)
| 고객 번호 | 고객 이름 | 주소1 | 주소2 | 전화 번호 |
|---|---|---|---|---|
| 00001 | 아이다 타카유키 | 도쿄도 신주쿠구 | 가부키초 x-x-x | 03-xxxx-xxxx |
| 00002 | 이토 미카 | 가나가와현 요코하마시 | 나카구 야마시타초 xx | 045-xxx-xxxx |
| 00003 | 우치다 코지 | 사이타마현 사이타마시 | 타카사고 xx-xx | 048-xxx-xxxx |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 판매일 | 고객 번호 | 상품1 | 상품2 | 상품3 | …… |
|---|---|---|---|---|---|
| 050115 | 00002 | 긴죠 灘 1병 | 특선 안주 | ||
| 050116 | 00001 | 고베 와규 세트 | |||
| 050116 | 00003 | 특가 생햄 | 홀 머스타드 | 마리 로랑생 | |
| 050117 | 00001 | 사츠마 흑돼지 햄 | |||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
데이터를 연결할 때 기준이 되는 항목을 키라고 부르며, 이 키는 모든 데이터에 고유해야 한다.
이러한 데이터베이스는 각 데이터베이스 내용 변경에 쉽게 대응할 수 있으며, 부분적인 등록 내용 변경이 이루어져도 최신 정보를 이용할 수 있다는 장점이 있다.
실제 업무에 사용되는 데이터베이스는 상품 목록 테이블 등이 별도로 설치되어 여러 개의 테이블이 연계되어 사용자에게 데이터를 제공하도록 설계된다. 이는 데이터 중복을 피하고 관리를 용이하게 하기 위함이다.
잘 설계된 데이터베이스에서는 정형문(정형 쿼리) 형태로 쿼리가 준비되어 사용자는 최신 데이터를 기반으로 한 표를 볼 수 있다.
응용 소프트웨어 형태로 사용될 경우, 그래픽 사용자 인터페이스(GUI)를 통해 사용자는 쿼리나 관계(릴레이션) 등을 거의 의식하지 않고 데이터를 활용할 수 있다.
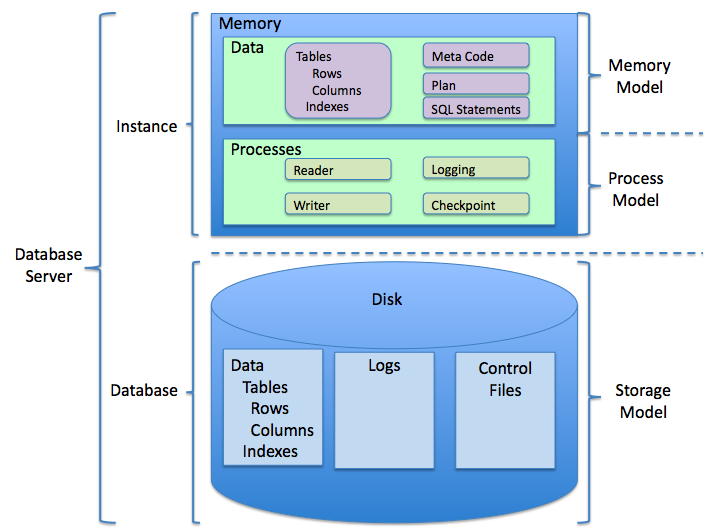
'''관계형 데이터베이스 관리 시스템'''(關係形 Database 關理 System, Relational Database Management System영어, '''RDBMS''')은 RDB를 관리하는 소프트웨어 또는 시스템이다.
E. F. 코드는 1970년 IBM에서 발표한 논문 "대규모 공유 데이터 뱅크를 위한 데이터의 관계형 모델"에서 "관계형" 용어를 처음 사용하고,[1] 이후 논문에서 "관계"의 의미를 정의했다. 관계형 데이터베이스 시스템 구성의 가장 잘 알려진 정의 중 하나는 코드의 12가지 규칙이다. 그러나 코드의 모든 규칙을 준수한 관계형 모델의 상업적 구현은 없었으며,[3] 해당 용어는 다음을 충족하는 더 광범위한 데이터베이스 시스템을 설명하는 데 사용되었다.
# 사용자에게 데이터를 관계(테이블의 모음, 각 테이블은 행과 열의 집합)로 표시.
# 표 형식 데이터를 조작하는 관계 연산자 제공.
1974년, IBM은 RDBMS 프로토타입 개발 연구 프로젝트인 System R 개발을 시작했다.[4][5] 최초의 RDBMS는 Multics Relational Data Store (1976년 6월)였다. Oracle는 1979년 Relational Software에서 출시되었으며, 현재는 오라클이다.[6] Ingres와 IBM BS12가 뒤따랐다. IBM Db2, SAP Sybase ASE, Informix도 RDBMS의 예시이다. 1984년에는 Macintosh용 최초의 RDBMS가 개발, 1987년 4th Dimension으로 출시되어 현재는 4D로 알려져 있다.[7]
관계형 모델을 비교적 충실하게 구현한 첫 번째 시스템은 다음과 같다.
| 고객 번호 | 고객 이름 | 주소1 | 주소2 | 전화 번호 |
|---|---|---|---|---|
| 00001 | 아이다 타카유키 | 도쿄도 신주쿠구 | 가부키초 x-x-x | 03-xxxx-xxxx |
| 00002 | 이토 미카 | 가나가와현 요코하마시 | 나카구 야마시타초 xx | 045-xxx-xxxx |
| 00003 | 우치다 코지 | 사이타마현 사이타마시 | 타카사고 xx-xx | 048-xxx-xxxx |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 판매일 | 고객 번호 | 상품1 | 상품2 | 상품3 | …… |
|---|---|---|---|---|---|
| 050115 | 00002 | 긴죠 灘 1병 | 특선 안주 | ||
| 050116 | 00001 | 고베 와규 세트 | |||
| 050116 | 00003 | 특가 생햄 | 홀 머스타드 | 마리 로랑생 | |
| 050117 | 00001 | 사츠마 흑돼지 햄 | |||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
두 데이터를 고객 번호로 관련짓고, 고객 이름 데이터를 요구하면 다음과 같다.
| 고객 이름 | 상품1 | 상품2 | 상품3 | …… |
|---|---|---|---|---|
| 아이다 타카유키 | 고베 와규 세트 | |||
| 아이다 타카유키 | 사츠마 흑돼지 햄 | |||
| 이토 미카 | 긴죠 灘 1병 | 특선 안주 | ||
| 우치다 코지 | 특가 생햄 | 홀 머스타드 | 마리 로랑생 | |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
판매일을 한정하여, 고객 번호로 관련짓고, 상품과 배송지 데이터를 요구하면 다음과 같다.
| 배송지 주소1+2 | 고객 이름 | 상품1 | 상품2 | 상품3 | …… |
|---|---|---|---|---|---|
| 도쿄도 신주쿠구 가부키초 x-x-x | 아이다 타카유키 | 고베 와규 세트 | |||
| 사이타마현 사이타마시 타카사고 xx-xx | 우치다 코지 | 특가 생햄 | 홀 머스타드 | 마리 | …… |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
데이터를 연결할 때 기준이 되는 항목을 '''키'''라고 하며, 이 키는 고유해야 한다. 이 예에서는 고객 번호가 키이다.[29]
이 방식은 데이터베이스가 개별적으로 존재하여 각 내용 변경에 쉽게 대응하고, 쿼리를 통해 상호 연결하여 부분적인 변경에도 최신 정보를 이용할 수 있다는 장점이 있다. 고객 번호 00001의 고객이 이사하여 주소가 변경된 경우, 고객 데이터베이스만 변경하면 된다.[29]
업무를 처리하는 데이터베이스는 상품 목록 테이블이 별도로 설치되어 상품의 정가 등이 관리되는 등 여러 테이블이 연계되어 사용자에게 데이터를 제공한다. 이는 데이터 중복성을 피하고 관리를 쉽게 하기 위함이며, 키에 의해 상호 연결된다.[29]
제대로 설계된 데이터베이스에서는 복수의 쿼리가 '''정형문''' 형태로 준비되어, 사용자는 준비된 정형 쿼리를 통해 최신 데이터를 기반으로 한 표를 볼 수 있다.[29]
응용 소프트웨어 형태에서는 그래픽 사용자 인터페이스(GUI) 등의 조작 화면을 통해 쿼리문이 조합, 생성되어 데이터베이스에 전달되고, 돌아온 데이터를 처리하여 화면에 표시하거나 파일 형식으로 출력, 제공되므로, 최종 사용자는 쿼리나 관계를 거의 의식하지 않는다.[29]
| 제품명 | 개발사 | 비고 |
|---|---|---|
| 오라클 DBMS | 오라클 | |
| MS SQL Server | 마이크로소프트 | |
| MS Access | 마이크로소프트 | |
| MySQL | ||
| 어프로치 | 로터스 소프트웨어 | |
| PostgreSQL | ||
| IBM DB2 | IBM | IBM SQL/DS도 있음 |
| 파라독스(Paradox) | 볼랜드 | dBASE IV도 있음 |
| Sybase | ||
| Informix | ||
| VMS/Rdb | ||
| 알티베이스 HDB | 알티베이스 | |
| 티베로 | 티맥스소프트 | |
| CUBRID | 서치솔루션 |
DB-Engines에 따르면, 2024년 12월 db-engines.com 웹사이트에서 가장 인기 있는 시스템은 다음과 같다.[26]
| 순위 | 제품명 |
|---|---|
| 1 | 오라클 데이터베이스 |
| 2 | MySQL |
| 3 | Microsoft SQL Server |
| 4 | PostgreSQL |
| 5 | Snowflake |
| 6 | IBM Db2 |
| 7 | SQLite |
| 8 | Microsoft Access |
| 9 | Databricks |
| 10 | MariaDB |
연구 회사 가트너에 따르면, 2011년 매출 기준 상위 5대 상용 소프트웨어 관계형 데이터베이스 공급업체는 오라클 (48.8%), IBM (20.2%), 마이크로소프트 (17.0%), SAP (사이베이스 포함) (4.6%), 테라데이터 (3.7%)였다.[27]
RDBMS의 주요 기술에는 관계 모델, 기본 키, 외래 키 등이 있다.
| 고객 번호 | 고객 이름 | 주소1 | 주소2 | 전화 번호 |
|---|---|---|---|---|
| 00001 | 아이다 타카유키 | 도쿄도 신주쿠구 | 가부키초 x-x-x | 03-xxxx-xxxx |
| 00002 | 이토 미카 | 가나가와현 요코하마시 | 나카구 야마시타초 xx | 045-xxx-xxxx |
| 00003 | 우치다 코지 | 사이타마현 사이타마시 | 타카사고 xx-xx | 048-xxx-xxxx |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| 판매일 | 고객 번호 | 상품1 | 상품2 | 상품3 | …… |
|---|---|---|---|---|---|
| 050115 | 00002 | 긴죠 灘 1병 | 특선 안주 | ||
| 050116 | 00001 | 고베 와규 세트 | |||
| 050116 | 00003 | 특가 생햄 | 홀 머스타드 | 마리 로랑생 | |
| 050117 | 00001 | 사츠마 흑돼지 햄 | |||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
위의 예시처럼, 관계형 데이터베이스는 목적에 맞춰 데이터를 연결하여 원하는 표를 얻을 수 있다는 큰 특징을 가지고 있다. 데이터를 연결할 때 기준이 되는 항목을 키라고 하며, 이 키는 모든 데이터에 고유해야 한다.
관계형 데이터베이스는 각 데이터베이스 내용의 변경에 쉽게 대응할 수 있고, 쿼리를 통해 최신 정보를 이용할 수 있다는 장점이 있다. 예를 들어, 고객의 주소가 변경된 경우 고객 데이터베이스만 변경하면 된다.
실제 업무에서는 상품 목록 테이블 등 여러 개의 테이블이 연계되어 데이터를 제공하도록 설계된다. 이는 데이터의 중복성을 피하고, 데이터를 더 쉽게 관리하기 위함이다.
한 번 제대로 설계된 데이터베이스에서는, 복수의 쿼리를 미리 정형문(정형 쿼리) 형태로 준비하여 사용자가 쉽게 최신 데이터를 기반으로 한 표를 볼 수 있도록 한다.
응용 소프트웨어의 형태가 되면, 그래픽 사용자 인터페이스(GUI) 등의 조작 화면을 통해 사용자는 쿼리나 관계를 거의 의식하지 않고 데이터를 이용할 수 있다.
[1]
학술대회
Portable Software Tools for Managing and Referencing Taxonomies
https://pubs.usgs.go[...]
2024-04-06
[2]
웹사이트
Relational Databases 101: Looking at the Whole Picture
http://www.agiledata[...]
2023-03-21
[3]
서적
Database in depth: relational theory for practitioners
O'Reilly
2005-05-05
[4]
서적
Funding a Revolution: Government Support for Computing Research
https://books.google[...]
National Academies Press
1999-01-08
[5]
서적
Fundamentals of Relational Database Management Systems
Springer
2008-02-13
[6]
저널
Oracle Timeline
http://www.oracle.co[...]
Oracle
2013-05-16
[7]
웹사이트
New Database Software Program Moves Macintosh Into The Big Leagues
https://www.chicagot[...]
2016-03-17
[8]
저널
A set theoretic data structure and retrieval language
https://dl.acm.org/d[...]
Association for Computing Machinery
2024-01-04
[9]
서적
SIGFIDET '74: Proceedings of the 1974 ACM SIGFIDET (Now SIGMOD) Workshop on Data Description, Access and Control: Data Models: Data-Structure-Set versus Relational
https://dl.acm.org/d[...]
Association for Computing Machinery
2024-01-04
[10]
서적
The Peterlee IS/1 System
https://scholar.goog[...]
IBM United Kingdom Scientific Centre
2024-01-04
[11]
저널
The Peterlee Relational Test Vehicle - A System Overview
[12]
저널
SRQL: Sorted Relational Query Language
http://pages.cs.wisc[...]
[13]
웹사이트
A Relational Database Overview
https://docs.oracle.[...]
[14]
서적
A universal relation model for a nested database
http://dx.doi.org/10[...]
Springer Berlin Heidelberg
2020-11-01
[15]
웹사이트
Gray to be Honored With A. M. Turing Award This Spring
http://www.microsoft[...]
Microsoft PressPass
2009-01-16
[16]
학술대회
The Transaction Concept: Virtues and Limitations
http://research.micr[...]
Tandem Computers
2006-11-09
[17]
서적
Distributed Transaction Processing: Concepts and Techniques
Morgan Kaufmann
[18]
저널
A Relational Model of Data for Large Shared Data Banks
[19]
서적
Database systems: a practical approach to design, implementation, and management
Pearson
[20]
서적
Database Systems – A Practical Approach to Design Implementation and Management
Pearson
2014-00-00
[21]
서적
Concepts of Database Management
Course Technology
2014-09-08
[22]
서적
Dateso 10; Database Trends and Directions: Current Challenges and Opportunities
https://citeseerx.is[...]
MATFYZPRESS
2010-04-21
[23]
웹사이트
NoSQL databases eat into the relational database market
https://www.techrepu[...]
2018-03-14
[24]
저널
Distributed database for SAA
1988-00-00
[25]
서적
Distributed Relational Database Architecture Reference
IBM Corp. SC26-4651-0
1990-00-00
[26]
웹사이트
DB-Engines Ranking of Relational DBMS
https://db-engines.c[...]
2024-12-01
[27]
뉴스
Oracle the clear leader in $24 billion RDBMS market
http://itknowledgeex[...]
2013-03-01
[28]
문서
关系数据库に含まれないデータベースは、[[NoSQL]] などを参照。
[29]
논문
A Relational Model of Data for Large Shared Data Banks
http://www.seas.upen[...]
IBM Research Laboratory, California
[30]
저널
A Relational Model of Data for Large Shared Data Banks
[31]
웹인용
A Relational Database Overview
https://docs.oracle.[...]
[32]
웹인용
Gray to be Honored With A. M. Turing Award This Spring
http://www.microsoft[...]
Microsoft PressPass
1998-11-23
[33]
학술대회
The Transaction Concept: Virtues and Limitations
http://research.micr[...]
Tandem Computers
1981-09-00
[34]
서적
Distributed Transaction Processing: Concepts and Techniques
Morgan Kaufmann
( 최근 20개의 뉴스만 표기 됩니다. )
본 사이트는 AI가 위키백과와 뉴스 기사,정부 간행물,학술 논문등을 바탕으로 정보를 가공하여 제공하는 백과사전형 서비스입니다.
모든 문서는 AI에 의해 자동 생성되며, CC BY-SA 4.0 라이선스에 따라 이용할 수 있습니다.
하지만, 위키백과나 뉴스 기사 자체에 오류, 부정확한 정보, 또는 가짜 뉴스가 포함될 수 있으며, AI는 이러한 내용을 완벽하게 걸러내지 못할 수 있습니다.
따라서 제공되는 정보에 일부 오류나 편향이 있을 수 있으므로, 중요한 정보는 반드시 다른 출처를 통해 교차 검증하시기 바랍니다.
문의하기 : help@durumis.com